S/ISO/PDF
PDF stands for Portable Document Format, which was created by Adobe[1], and currently maintained by the International Organization for Standardization (ISO) as an open source international standard [2].
Some commonly used specialized PDF types include:
ISO 14289/PDF/UA for accessible PDF documents and processors (extends PDF/A conformance level A)
ISO 15930/PDF/X for printing
ISO 19005/PDF/A for long-term archiving [3]
Sub-parts:
ISO 19005-1:2005/PDF/A-1 (based on PDF v1.4)
ISO 19005-2:2011/PDF/A-2 (based on PDF v1.7)
ISO 19005-3:2012/PDF/A-3 (add file)
ISO 19005-4:2020/PDF/A-4 (based on PDF v2.0)
Not allow: audio, video, 3d objects, JS, certain actions, encryption, non-standard metadata
Require: embedding font with proper license
ISO 24517/PDF/E for representing engineering documents (CAD, etc.).
For regulatory submission, FDA currently support “PDF versions 1.4 through 1.7, PDF/A-1 and PDF/A-2”[4]. Steps for creating and validating PDF/A files can be found in reference [5],[6].
The module stdiso.pdfsummary depends on package pypdf [7].
The module stdiso.pdfsummary include functions for creating summaries about a specified PDF file.
PDF File Summary
To use mtbp3.stdiso:
from mtbp3.stdiso.pdfsummary import pdfSummary
pfr = pdfSummary(path="")
print(pfr.get_summary_string())
File name: attention.pdf
File size (byte): : 2215244
File creation date: 2024-04-10 21:11:43+00:00
File modification date: 2024-04-10 21:11:43+00:00
PDF version: 1.5
Number of pages: : 15
Number of images in individual pages: : [0, 0, 1, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Total number of images: : 3
If the path left as empty, an example pdf file will be loaded for illustration. More details about the example pdf can be found here: https://arxiv.org/abs/1706.03762.
To view the outline tree:
print(pfr.show_outline_tree())
attention.pdf
├── Introduction
├── Background
├── Model Architecture
│ ├── Encoder and Decoder Stacks
│ ├── Attention
│ │ ├── Scaled Dot-Product Attention
│ │ ├── Multi-Head Attention
│ │ └── Applications of Attention in our Model
│ ├── Position-wise Feed-Forward Networks
│ ├── Embeddings and Softmax
│ └── Positional Encoding
├── Why Self-Attention
├── Training
│ ├── Training Data and Batching
│ ├── Hardware and Schedule
│ ├── Optimizer
│ └── Regularization
├── Results
│ ├── Machine Translation
│ ├── Model Variations
│ └── English Constituency Parsing
└── Conclusion
Work with Images
We can see that there is one image in the 3rd page from the summary above. To extract the first image on the 3rd page:
img = pfr.get_image(page_index=2, image_index=0, outfolder='')
print(type(img))
print(img.size)
<class 'PIL.PngImagePlugin.PngImageFile'>
(1520, 2239)
display(img.resize((300, int(300*img.size[1]/img.size[0]))))
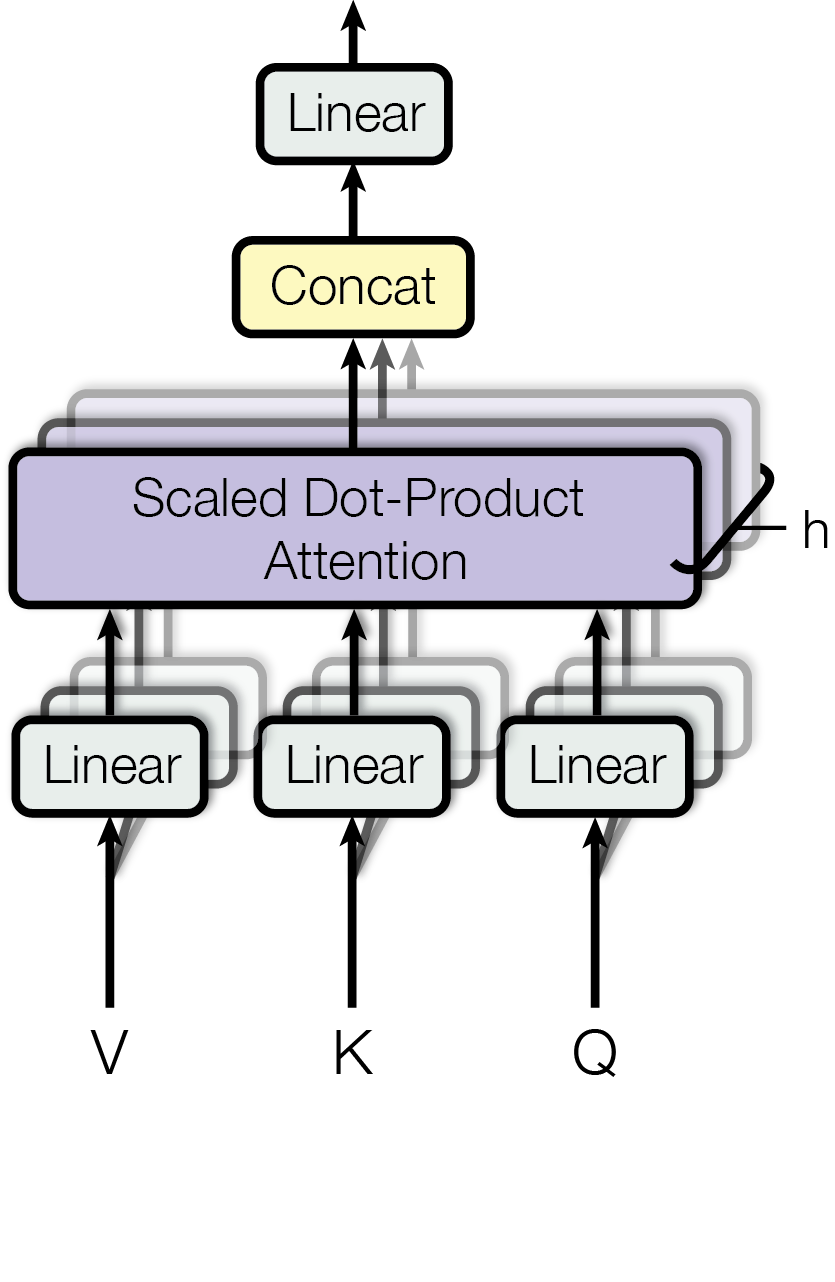
The resize() function above resized the figure before displaying. Use display(img) in Jupyter if resizing is not required.
To save the 2nd image on the 4th page to a file, add an existing folder path using outfolder='add_path_here':
img_path = pfr.get_image(page_index=3, image_index=1, outfolder='.')
The function get_image() returns a file path instead of the image when the outfolder option is not an empty string.
To read and display the saved image file in Jupyter:
from IPython.display import Image
img = Image(filename=img_path, width=300)
display(img)